
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- robux
- 오라클 데이터베이스 내장함수
- 나는 어디로?
- 파이썬 TypeError
- 라이브러리 vs 패키지
- 갤럭시탭 with Pen
- 주상복합용지 분양
- 상업시설용지 분양
- 데이터 리터러시
- 임대소득외 추가소득이 있을 경우
- 다주택임대
- 가장 인기있는 파이썬 라이브러리
- chatgpt 100% 신뢰금지
- Python
- 종합소득세
- bard 100% 신뢰금지
- 2룸 오피스텔 투자
- 오피스텔투자
- PostgreSQL
- 공개서적
- 종합과세
- Google vs OpenAI
- 가장 인기있는 파이썬 패키지
- 가장 많이 사용되는 파이썬 패키지
- 소형주택 세액감면
- 전세보증보험
- 주택임대사업자
- Google vs MicorSoft
- chatgpt vs bard
- 가장 많이 사용되는 파이썬 라이브러리
All thing of the world!
Oracle GROUPING 설명 : 오라클 함수 본문
1. 함수의 목적
Oracle GROUPING은GROUP BY의 확장형태인 ROLLUP과 CUBE등은 모든 값의 집합이 NULL로 표시되는 SUPERAGGREGATE행을 표시하는데, SUPERAGGREGATE행인지 아니면 일반 GROUP BY에 의한 행인지 구분할 수 있도록 한다.
2. 샘플을 통한 개념 퀵뷰
GROUPING() 함수의 결과값이 1이면 SUPERAGGREGATE행이다.
이러한 SUPERAGGREGATE값을 가지고 모든 값의 집합인 ALL DEPARTMENTS로 표시하도록 DECODE문을 사용했다.
ALL Jobs 마찬가지 원리로 구현했다.
SELECT
DECODE(GROUPING(department_name), 1, 'ALL DEPARTMENTS', department_name)
AS department,
DECODE(GROUPING(job_id), 1, 'All Jobs', job_id) AS job,
COUNT(*) "Total Empl",
AVG(salary) * 12 "Average Sal"
FROM employees e, departments d
WHERE d.department_id = e.department_id
GROUP BY ROLLUP (department_name, job_id)
ORDER BY department, job;

3. 사용방법
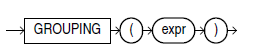
4. 함수 PARAMETER 설명
[expr]
평가할 컬럼을 입력하는 파라미터이다.
GROUP BY의 컬럼과 반드시 일치해야 한다.
반환값이 1이라면 SUPERAGGREGATE 컬럼이란 뜻이고, 0이라면 일반 GROUP BY에 의해 생성된 ROW라고 본다.
반환값은 숫자형이다.
5. 다양한 샘플표현
'IT > Oracle DBMS' 카테고리의 다른 글
| Oracle FIRST_VALUE 설명 : 오라클 함수 (0) | 2021.04.06 |
|---|---|
| Oracle GREATEST 설명 : 오라클 함수 (0) | 2021.04.06 |
| Oracle GROUP_ID 설명 : 오라클 함수 (0) | 2021.04.06 |
| Oracle INITCAP 설명 : 오라클 함수 (0) | 2021.04.06 |
| Oracle LAST 설명 : 오라클 함수 (0) | 2021.04.06 |



